Python란?
Python은 배우기 쉽고 강력한 프로그래밍 언어입니다.
효율적인 고급 데이터 구조와 객체 지향 프로그래밍에 대한 간단하지만 효과적인 접근 방식을 가지고 있습니다.
Python의 세련된 구문 및 동적 유형 지정은 해석된 특성과 함께 대부분의 플랫폼에서 많은 영역에서 스크립팅 및 신속한 응용 프로그램 개발에 이상적인 언어입니다.
출처: Python 튜토리얼
Python 시작하기!
1) Python 3.8.6 버전 다운로드 하기
1. 아래의 링크를 클릭하여 다운로드를 합니다!
https://www.python.org/ftp/python/3.8.6/python-3.8.6-amd64.exe
2. Add Python 3.8 to PATH 를 체크합니다.

2) 프로젝트 만들기
1. PyCharm을 실행시켜주신 후 파일 → new project를 클릭합니다.
위 처럼 해주시면 가상 환경도 같이 생성됩니다!
오류!
만약 위 처럼 가상 환경을 생성하지 못했다고 경고창이 뜰 경우 파이참 최신버전의 버그가 있는 것으로 추정되어 기존 파이참을 삭제한 뒤, 아래 링크에서 파이참 2.2버전으로 다운그래이드 하시면 해결됩니다!
Other Versions - PyCharm
Get past releases and previous versions of PyCharm.
www.jetbrains.com
Python 기초
1) 변수 & 기본연산
1. 변수지정
Javascript와는 다르게 Python에선 변수 지정할 때 따로 let, var, const 없이 그냥 지정이 가능하다.
a = 3 # 3을 a에 넣는다
b = a # a를 b에 넣는다
a = a + 1 # a+1을 다시 a에 넣는다
num1 = a*b # a*b의 값을 num1이라는 변수에 넣는다
num2 = 99 # 99의 값을 num2이라는 변수에 넣는다
name = 'bob' # 변수에는 문자열이 들어갈 수도 있고,
num = 12 # 숫자가 들어갈 수도 있고,
is_number = True # True 또는 False -> "Boolean"형이 들어갈 수도 있습니다.
# 변수의 이름은 마음대로 지을 수 있음!
2. 리스트 형 & 딕셔너리 형
리스트와 딕셔너리는 Javascript와 동일하다.
#List 형
a_list = []
a_list.append(1) # 리스트에 값을 넣는다
a_list.append([2,3]) # 리스트에 [2,3]이라는 리스트를 다시 넣는다
print(a_list)
>[1, [2, 3]]
#Dictionary 형
a_dict = {}
a_dict = {'name':'bob','age':21}
a_dict['height'] = 178
print(a_dict)
>{'name': 'bob', 'age': 21, 'height': 178}
#Dictionary 형과 List형의 조합
people = [{'name':'bob','age':20},{'name':'carry','age':38}]
person = {'name':'john','age':7}
people.append(person)
print(people)
>[{'name': 'bob', 'age': 20}, {'name': 'carry', 'age': 38}, {'name': 'john', 'age': 7}]3. 함수
Python에서의 함수 정의는 Javascript와 달리 def로 정의를 할 수 있다.
Javascript :
function f(x) {
return 2*x+3
}
Python :
def f(x):
return 2*x+3
2) 조건문
Python 조건문도 if / else로 구성되어 있습니다.
def is_adult(age):
if age > 20:
print('성인입니다') # 조건이 참이면 성인입니다를 출력
else:
print('청소년이에요') # 조건이 거짓이면 청소년이에요를 출력
is_adult(30)
>성인입니다3) 반복문
Python에서의 반복문은, 리스트의 요소들을 하나씩 꺼내쓰는 형태입니다. 즉, 반복문을 사용하려면 무조건 리스트와 함께 사용해야 합니다!
fruits = ['사과','배','배','감','수박','귤','딸기','사과','배','수박']
count = 0
for fruit in fruits:
if fruit == '사과':
count += 1
print(count)
>2Crawling(크롤링) 해보기
1) Python package 설치하기
1. package란?
Python 에서 패키지는 모듈(일종의 기능들 묶음)을 모아 놓은 단위입니다. 이런 패키지 의 묶음을 라이브러리 라고 볼 수 있습니다. 지금 여기서는 외부 라이브러리를 사용하기 위해서 패키지를 설치합니다.
패키지를 다운받을 경우 venv(가상 환경)에 설치가 됩니다. 여기서 venv(가상 환경)이란,
virtual environment (가상 환경)
파이썬 사용자와 응용 프로그램이, 같은 시스템에서 실행되는 다른 파이썬 응용 프로그램들의 동작에 영향을 주지 않으면서, 파이썬 배포 패키지들을 설치하거나 업그레이드하는 것을 가능하게 하는, 협력적으로 격리된 실행 환경입니다.
출처:파이썬 공식 용어집 - 가상 환경
용어집 — Python 3.10.8 문서
같은 형의 두 인자를 수반하는 연산이 일어나는 동안, 한 형의 인스턴스를 다른 형으로 묵시적으로 변환하는 것. 예를 들어, int(3.15)는 실수를 정수 3으로 변환합니다. 하지만, 3+4.5 에서, 각 인자
docs.python.org
2. package install 하기
파일 → 설정 → project → Python interpreter에 진입한 후, "+"버튼을 클릭하여 설치할 수 있습니다.
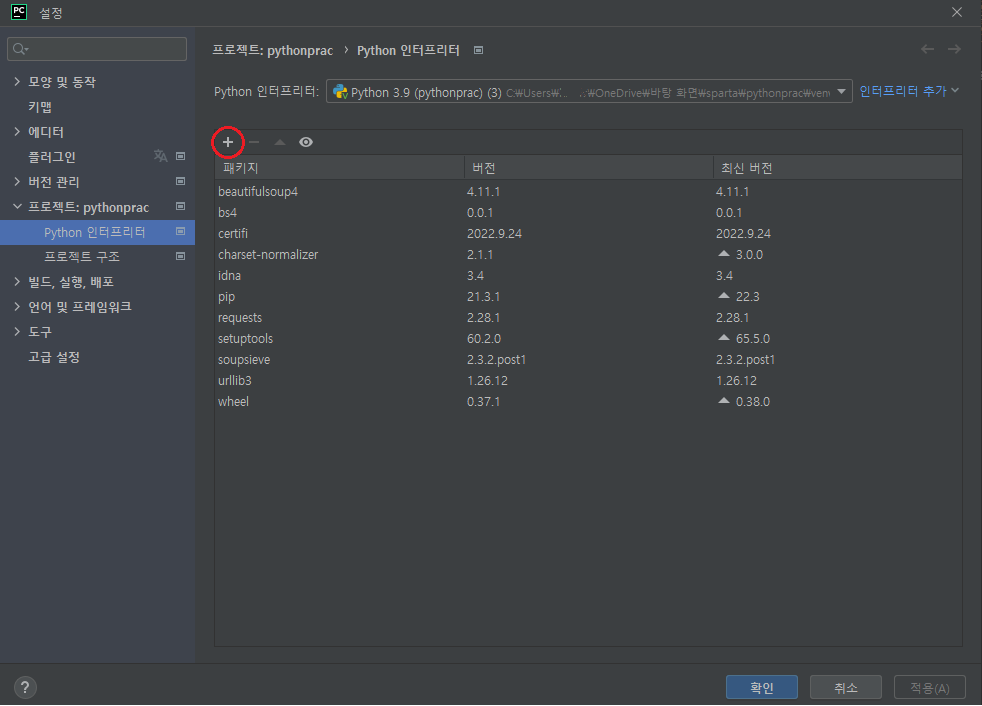
혹은 터미널에 직접 입력하여 install 할 수 있습니다.
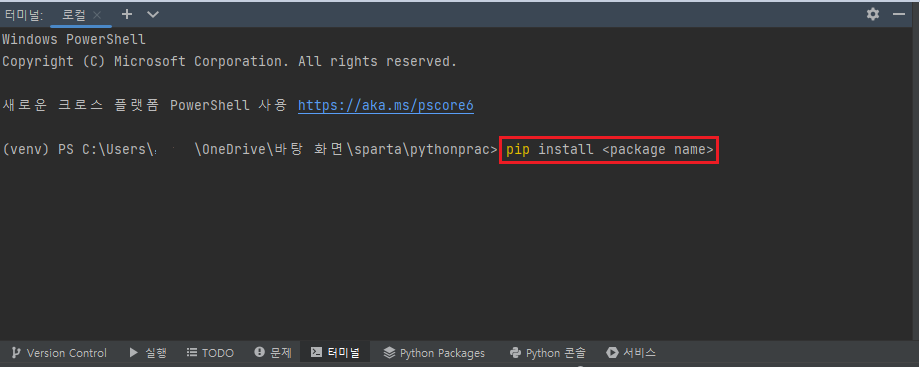
2) 웹스크래핑(크롤링) 기초
1. 크롤링 기본 세팅
import requests
from bs4 import BeautifulSoup
# 타겟 URL을 읽어서 HTML를 받아오고,
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
# HTML을 BeautifulSoup이라는 라이브러리를 활용해 검색하기 용이한 상태로 만듦
# soup이라는 변수에 "파싱 용이해진 html"이 담긴 상태가 됨
# 이제 코딩을 통해 필요한 부분을 추출하면 된다.
soup = BeautifulSoup(data.text, 'html.parser')
2. 영화 제목 가져와보기
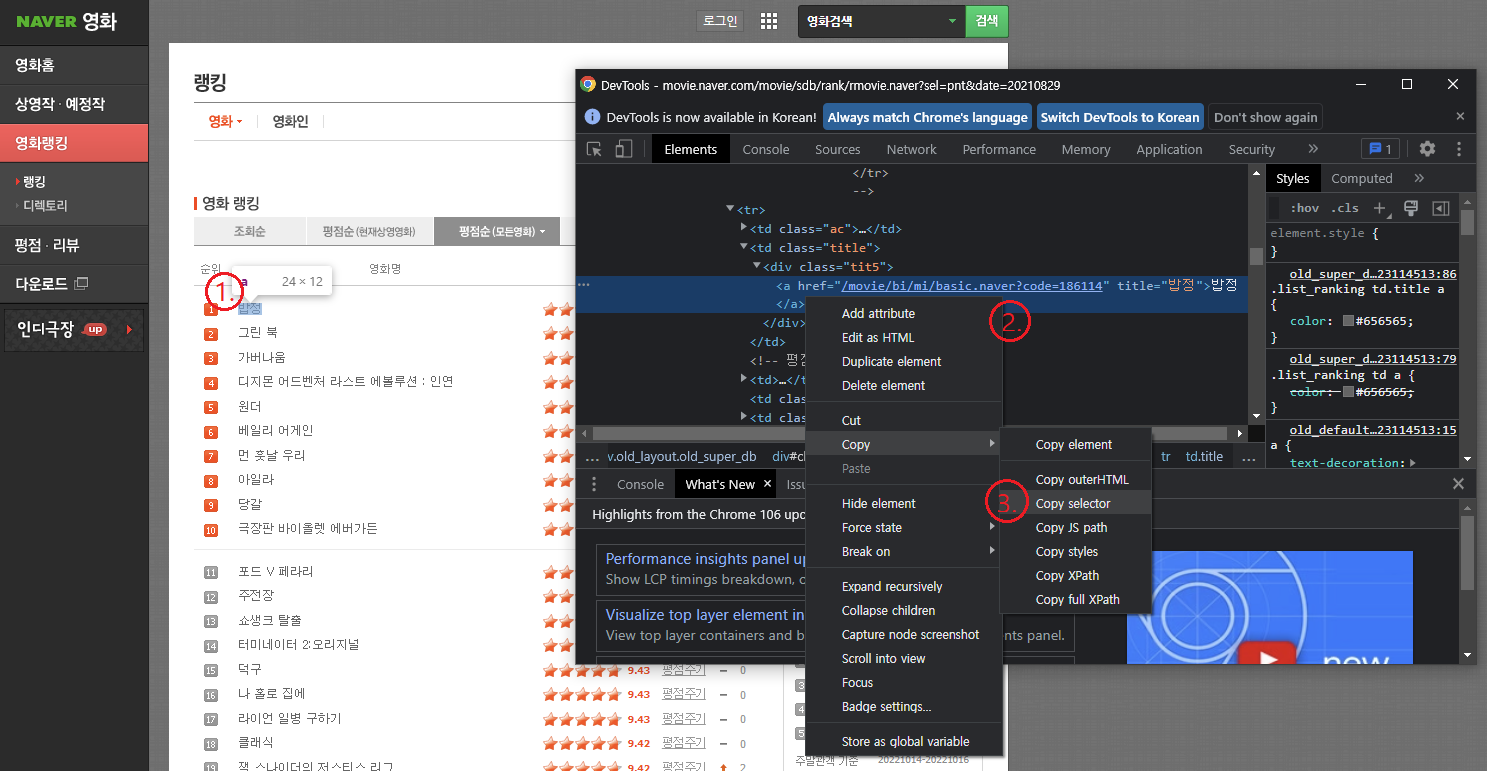
1. 원하는 부분에서 마우스 오른쪽 클릭 → 검사
2. 원하는 태그에서 마우스 오른쪽 클릭
3. Copy → Copy selector로 선택자를 복사할 수 있음
BeautifulSoup package를 이용하여 영화 제목들을 가져와 보겠습니다.
#가져온 선택자들을 확인해 보면 중복이 되는 부분을 확인할 수 있습니다.
#old_content > table > tbody > tr:nth-child(2) > td.title > div > a
#old_content > table > tbody > tr:nth-child(3) > td.title > div > a
# select를 이용해서, tr들을 불러오기
movies = soup.select('#old_content > table > tbody > tr')
# movies (tr들) 의 반복문을 돌리기
for movie in movies:
# movie 안에 a 가 있으면,
a_tag = movie.select_one('td.title > div > a')
if a_tag is not None:
# a의 text를 찍어본다.
print (a_tag.text)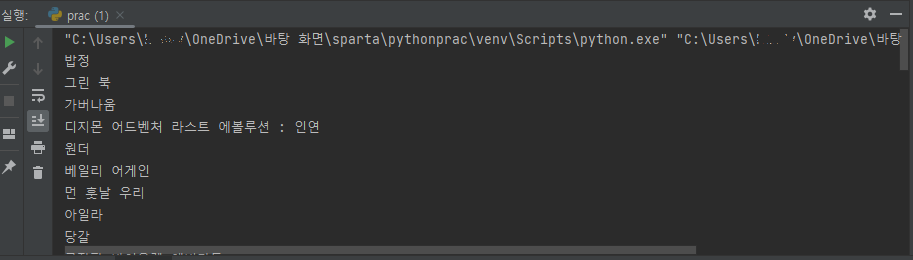
이렇게 네이버영화 페이지에 있는 영화 제목들을 성공적으로 가져온 것을 볼 수 있습니다!!
'SpartaCodingClub > 사전캠프' 카테고리의 다른 글
| [스파르타코딩클럽] 사전캠프 7일차 - MongoDB (0) | 2022.10.23 |
|---|---|
| [스파르타코딩클럽] 사전캠프 5일차 - Ajax (0) | 2022.10.21 |
| [스파르타코딩클럽] 사전캠프 4일차 - JQuery!! (0) | 2022.10.20 |
| [스파르타코딩클럽] 사전캠프 3일차 - Javascript (0) | 2022.10.19 |
| [스파르타코딩클럽] 사전캠프 2일차 - CSS & 부트스트랩 적용하기! (0) | 2022.10.18 |




댓글